ElasticSearch_Query
來源:200-Areas/210-工程師修煉/ELK/ELK_Python_Client
ElasticSearch Query
檢測工具進入 Kibana 網站點選左上角漢堡,Management --> Dev Tools,就可是進行測試
CAT
快速搜尋狀態
allocation
查詢每一台伺服器硬碟使用狀態,使用avail 硬體空間偵測
GET /_cat/allocation?v
shards disk.indices disk.used disk.avail disk.total disk.percent host ip node
101 28.2gb 54.7gb 37.9gb 92.7gb 59 10.37.91.22 10.37.91.22 node-2
101 39.2gb 59.4gb 67.4gb 126.9gb 46 10.37.91.21 10.37.91.21 node-1
100 37gb 58gb 34.6gb 92.7gb 62 10.37.91.23 10.37.91.23 node-3
- shards:分片數
- disk.indices:索引index佔用的空間大小
- disk.used:已用磁碟空間
- disk.avail:可用磁碟空間
- disk.total:磁碟空間總量
- disk.percent:磁碟已使用百分比
- host:節點主機位址
- ip:節點ip
- node:節點名稱
Search API
| 語法 | 範圍 |
|---|---|
/_search |
cluster 上所有的 index |
/index1/_search |
index1 |
/index1,index2/_search |
index1 + index2 |
/index*/_search |
以 index 開頭的 index |
POST /Your-index-name-*/_search
{
"sort": [{"log_timestamp":"asc"}], // 針對 number 、 date 最好
"from": 1, // 頁數
"size": 1, // 大小
"query": {
"wildcard": {
"page.keyword": "*.php"
}
},
"_source":["page","port","log_timestamp"]
}
Result
{
"took" : 151,
"timed_out" : false,
"_shards" : {
"total" : 46,
"successful" : 46,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 644,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "ob-iis-obweb01-x-2023.03.07",
"_type" : "_doc",
"_id" : "V5VTt4cBZGDjxhXyJ8IX",
"_score" : 1.0,
"_source" : {
"log_timestamp" : "2023-03-07T17:19:21.000Z",
"port" : "80",
"page" : "/011.php"
}
}
]
}
}
- took – 查詢花費時長(毫秒)
- timed_out – 請求是否超時
- _shards – 搜索了多少分片,成功、失敗或者跳過了多個分片(明細)
- max_score – 最相關的文件分數
- hits.total.value - 找到的文件總數
- hits.sort - 文件排序方式 (如沒有則按相關性分數排序 )
- hits._score - 文件的相關性算分 ( 沒有算分 )match_all
Relevance Scores
The relevance score is a positive floating point number, returned in the metadata field of the search API. The higher the , the more relevant the document. While each query type can calculate relevance scores differently, score calculation also depends on whether the query clause is run in a query or filter context._score``_score
相關性分數是一個正浮點數,在搜索 API 的元數據字段中返回。越高,文檔越相關。
雖然每種查詢類型可以不同地計算相關性分數,但分數計算還取決於查詢子句是在查詢還是過濾器上下文中運行。_score
Query context 與 Filter context 差異
-
全文匹配:針對 text 類型的字段進行全文檢索,會對查詢語句先進行分詞處理,如 match,match_phrase 等 query 類型
-
單詞匹配:不會對查詢語句做分詞處理,直接去匹配字段的倒排索引,如 term,terms,range 等 query 類型
-
Query 會提供
Relevance Scores判斷相關性、 filter 就是提供Yes/No -
Query 因為會提供 Relevance Scores、排序、需要根據
全部資料進行分析,無法快取,filter 則有快取 -
Query 使用 bool的
must、Should可增加權重,filter 則使用term、range進行篩選
Compound Queries
Bool Query
Boolean query | Elasticsearch Guide [8.8] | Elastic
Elasticsearch 之 Filter 與 Query 有啥不同? - 武培軒 - 博客園 (cnblogs.com)
- must:必須匹配,貢獻算分
- should:選擇性匹配,貢獻算分
- must_not:查詢字句,必須不能匹配
- filter:必須匹配,不貢獻算分
POST _search
{
"query": {
"bool" : {
"must" : {
"term" : { "user.id" : "kimchy" }
},
"filter": {
"term" : { "tags" : "production" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [
{ "term" : { "tags" : "env1" } },
{ "term" : { "tags" : "deployed" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
minimum_should_match
You can use the minimum_should_match parameter to specify the number or percentage of should clauses returned documents must match.
If the bool query includes at least one should clause and no must or filter clauses, the default value is 1. Otherwise, the default value is 0.
Boosting Query
相關度查詢
Boosting query | Elasticsearch Guide [8.8] | Elastic
- 當 boost > 1 時,打分的相關度相對性提升
- 當 0 < boost < 1 時,打分的權重相對性降低
- 當 boost < 0 時,貢獻負分
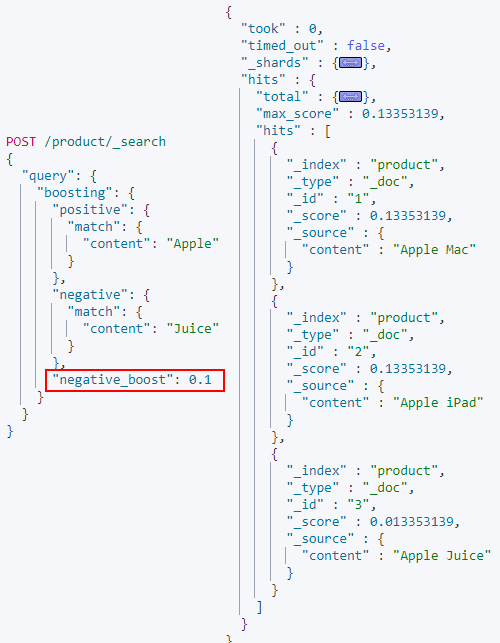
Function score query
The function_score allows you to modify the score of documents that are retrieved by a query. This can be useful if, for example, a score function is computationally expensive and it is sufficient to compute the score on a filtered set of documents.
自定義score分數,尤其是score計算過慢的時候特別有效。
Full Text Queries
The full text queries enable you to search analyzed text fields such as the body of an email. The query string is processed using the same analyzer that was applied to the field during indexing.
Match Query
進行分詞之後再進行搜尋
POST /users/_search
{
"query": {
"match": {
"title": "wupx huxy"
"operator": "and"
}
}
}
Match_phrase的 slop: 1 表示可接受中間有一個其他字元
POST /movies/_search
{
"query": {
"match_phrase": {
"title":{
"query": "one love"
"slop":1
}
}
}
}
Term
不進行分詞處理
POST /users/_search { "query": { "term": { "username":"wupx" } } } // 單一字元
POST /users/_search { "query": { "terms": { "username": [ "wupx", "huxy" ] } } } // 多字元查詢
query_string & simple_query_string
simple 會忽略錯誤語法, 可使用 +代替AND、|代替OR、-代替NOT
POST users/_search
{
"query": {
"query_string": {
"default_field": "username",
"query": "wupx AND huxy"
}
}
}
POST users/_search
{
"query": {
"simple_query_string": {
"query": "wu px",
"fields": ["username"],
"default_operator": "AND"
}
}
}
Geo Queries
Elasticsearch supports two types of geo data: geo_point fields which support lat/lon pairs, and geo_shape fields, which support points, lines, circles, polygons, multi-polygons, etc.
根據經緯度搜尋、geo_shape可以根據點、線、圓圈、多邊形進行搜尋(資料內要有)
其他 Queries
Query 總類非常多,有需要再去查就好
相關連結
200-Areas/210-工程師修煉/ELK/Aggregations
參考文件
[Day11] 技術指標計算 - 用 Python-client 搜尋 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天 (ithome.com.tw)
Day 7 Elasticsearch基本設定及查詢 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天 (ithome.com.tw)