限時搶購
來源: 📖 電子書/超大流量分布式系统架構解决方案:人人都是架構師2.0
解決問題
- 降低下游存儲系統的負載壓力
- 提升系统的回應速度。
快取方式
本地快取
本地快取的優點非常明显,那就是讀/寫性能非常好,但它痛是也存在如下兩個痛点:
- 佔用OS系统的記憶體資源
- 資料一致性問題
分布式
分布式快取雖然是以犧牲一定的性能(存在網路I/O開校)為代價,但卻可以换取無限延伸的儲存容量,以及數據一致性
基於RedisCluster模式實現Sharding
分布式场景下三种最常见的路由算法,如下所示:
- Hash算法
- Consistent Hash算法
- 分槽算法
高併發 Read
書中提供如下两種配套解决方案:
● 多級快取方案;
● RedisCluster模式一主多從讀/寫分離方案
多級快取方案
當分布式快取因熱點問題導致出现單點瓶頸時,本地快取就可以派得上用場了,作者在生產環境中正是结合本地快取+分布式快取组合時間的多級快取方案来共同應對限 時搶購場景下同一熱賣商品的高併發讀難題,如圖4-6所示。
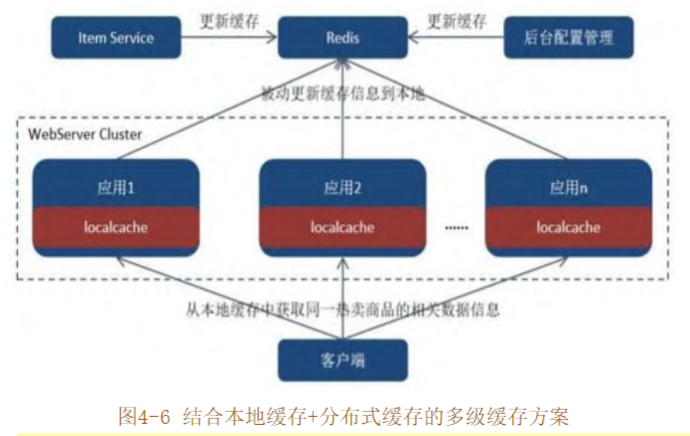
對於分布式快取而言,在數據的分布和用户的訪問請求都是相对均匀的情况下,我们確實可以通过擴展集群節點就能够無限延伸分布式缓存的整體容量,但是當出現熱點問題,流量訪問相對集中時,再通過水平擴展快取節點則無法有效對應,而本地快取卻非常適合這樣的業務場景
作者不建議把所有的商品信息都快取在本地快取中。例如,訪問熱度不高的商品可以直接訪問分布式快取,而本地快取中儲存更多的是訪問热度较高的熱賣商品
由於商品的圖片、影片等資源都快取在CDN中,因此本地快取中理論上只需要快取以下兩類數據
-
商品詳情
商品詳情這類變化頻率較低的數據,一般在限時搶購活動開始之前就可以全量推送到所有參與限時搶購的WebServer節點的本地快取,設定較長的快取過期時間中,直到活動結束 -
商品庫存
將快取的過期時間設定得相對短一些,一般來說幾秒鐘後就可以從分布式快去中取得最新的庫存數據
大家看到這裡時是否會產生一個疑問?本地快取中儲存的商品庫存與實際商品庫存之間可能會因為時差而造成數據落差,這樣是否會導致超賣?
數據髒讀
最終扣減庫存時在提示用戶所購買的商品已經賣光即可
(事實上,接入層Ngxing中也可以再快取一份 下游商品詳情介面的資料,不過其過期時間務必要小於本地快取所設定的過期時間,盡可能將流量檔案系統上游)
本地快取的更新策略可以分為
-
被動更新
時間到就更新,務必確保單機只能夠允許一個執行序在執行操作,避免快取失效的瞬間大量請求穿透到分布式快取上,引起雪崩式效應。(全部機器都在更新快取變成穿透到分布式) -
主動更新
快取更新策略
基於 GuavaCache
- expireAfterAccess:快取項在單位時間內未發生過讀/寫操作即被回收
- expireAfterWrite:快取項在單位時間内未被更新即被回收
每個執行序必須輪流地經歷取鎖、取值,以及釋放鎖的過程,這樣會存在一定程度上的性能耗損 - refreshAfterWrite:快取項離上一次更新操作多久之後被更新
那就是refreshAfterWrite機制並不能夠嚴格地確保返回值都是新值。
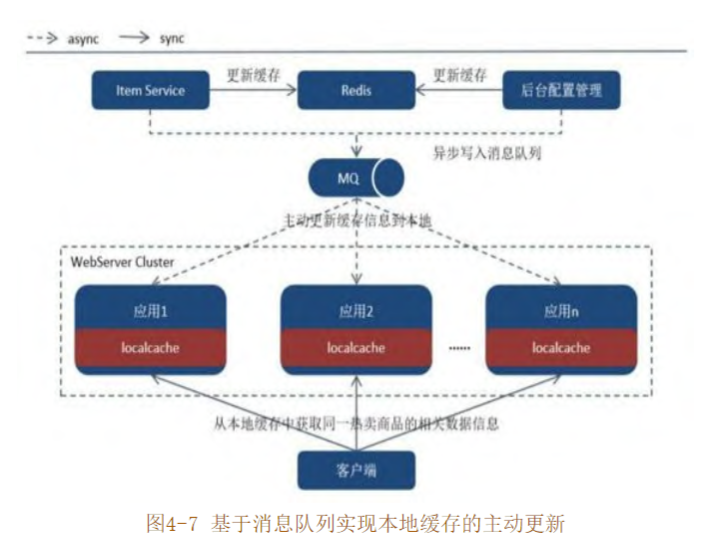
快取搭配MQ
想縮短本地快取與分布式快取之間數據不一致的空窗期,本書還提供另一種本地快取更新策略,那就是基於消息列隊的主動更新更新策略
作法
通過後台設定管理或者商品修改觸發 分佈式快取中的商品數據後,再把消息非同步寫入到消息隊列中,這樣一來,所有訂閱了目標Topic的Customer 就都可以取得最新的商品數據並更新本地快取項目
引入消息隊列,還需要增加額外的工作成本和系統當機風險
快取穿透思考
本地+分佈快取,但是本地更新快取空窗期,把分布式快取打掛
商品SKU特別多的狀況下,電商平台幾乎很難全部都放到本地快取,只會對於熱賣商品做優化。使用多級快取就會面臨一個問題,如何分配熱點key作者建議集中管理在配置中心內。一定要請行銷人員提供熱賣商品的sku編號,不然有幾個商品缺少就會被打掛....
如果設定的好,流量會平均分配在本地快取,降低分布式快取的負擔,處於比較平穩的水位。但是往往事情都不會這麼順利,所以要注意的是造成快取穿透如何避免雪崩式效應
大型的電商企業不會搭建業務特歲的熱點自動發現平台。簡單來說交易系統產生的相關數據 + 上游系統Nginx相關數據使用非同步的方式寫入Log系統中,然後統計數據之後把這些熱門商品寫到本地快取,當然還是可能在沒統計出來前,就被打掛了。
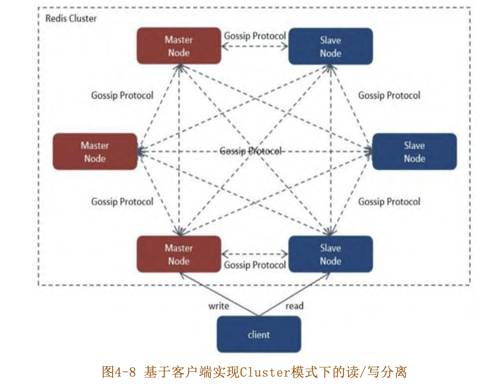
RedisCluster模式下的讀寫分離
這邊他介紹Java的Lib,使用讀寫分離,只要可以用C#達到Cluster讀寫分離又可以自動擴展就好。