分庫分表方案
關聯式資料庫架構演變
- 單一資料庫的TPS/QPS越來越低
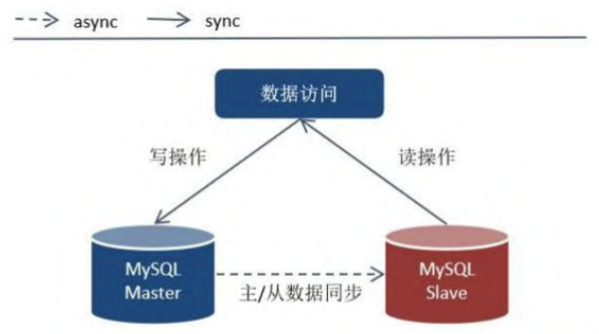
- 讀寫分離(一主一從,一主多從)
根據八二法則,80%的讀取,20%寫入
- 資料庫垂直分庫
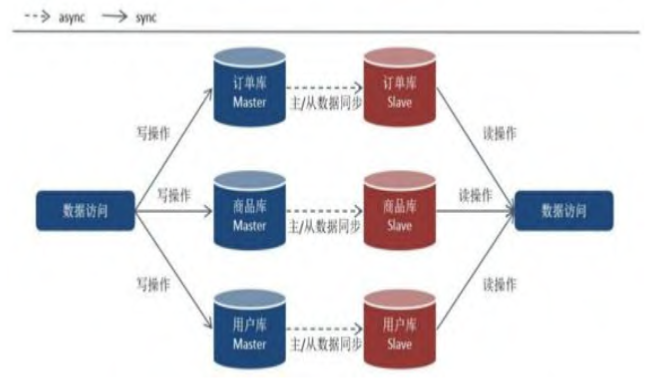
根據業務本身切割(訂單、產品、會員),再進行讀寫分離,單一張Table 超過 500萬筆資料就會造成讀取效能瓶頸,即使建立索引也是一樣。
Insert、Update不影響是因為,順序寫進去。
- 水平分庫與水平分表
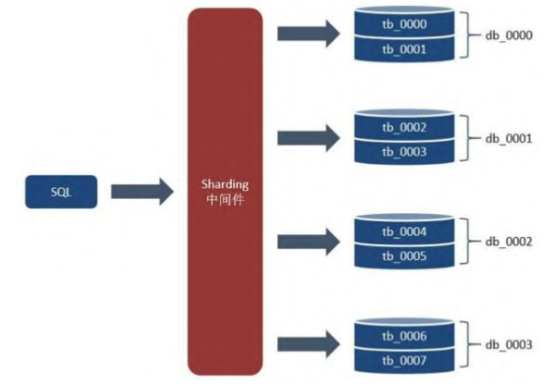
單張Table數據量過大的最終解決方案。- 水平分表(Sharding):將一張Table分很多張表(如 tab_0000、tab_0001、tab_0002..)
- 分庫+分表:將分表後的Table按照某種特定的算法跟規則分散到其他邏輯相關的DB(如:DB_0000,DB_0001,DB_0002),只是相對執行比較複雜,需要Sharding中間件負責數據路由的工作。
假設又到達瓶頸,DBA只需要針對現有的業務進行分庫和紛表水平擴展。
MySQL Sharding 與 MySQL Cluster的區別
- Cluster 費用貴,針對全部資料進行併行處理
- Sharding 經濟實惠,技術成熟,不儘可以提升DB的併行處理能力,還可以解決單一Table數據量過大造成的瓶頸
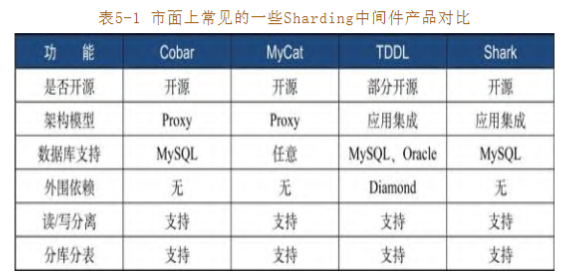
Sharding 中間件
選擇基於Proxy架構的sharding 中間件,可靈活實現關聯式資料庫協議,滿足個性化制定,做到一定程度的通用不限於任何資料庫
資料庫HA方案
待補
訂單業務冗餘表處理
相同資料寫入不同Table或是資料庫怎樣處理
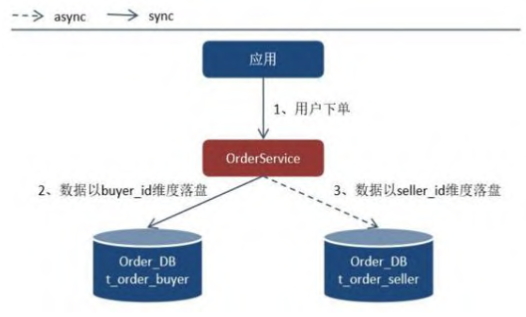
作者這邊舉例,因為業務垂直分庫之後,就會針對不同資料庫進行多次的單一查詢,盡量避免單一查詢多個Table的Join問題。以電子商務的場景來看,賣家訂單、買家訂單,都會有共同的資料訂單,實務的做法就是兩邊都寫一份。
但兩個可能是不同的Table或DB,如何確保最終一致性?
同步寫入
但缺點很明顯,多一倍的寫入時間,如果對系統的TPS嚴格要求,可以選擇非同步寫入
非同步寫入
當寫到第一張Table的時候,啟動一個非同步執行續負責寫入,或是寫入MQ,由Custemer負責寫入。
注意:這邊沒有辦法確保最終一致性
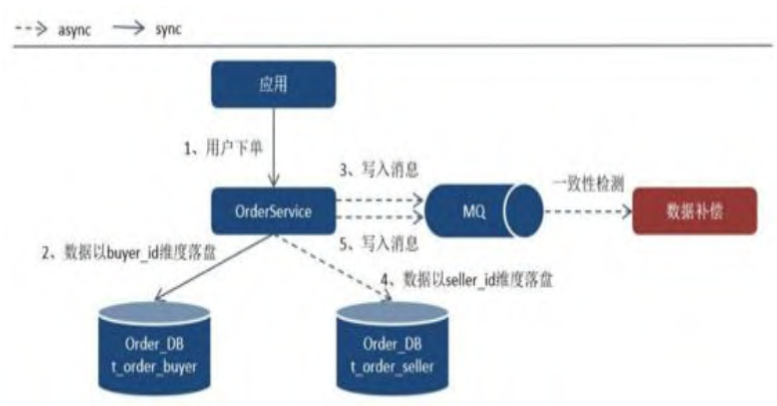
最終一致性解法
對於可以接受短期不一致的業務場景來說,最終一致性或許是最佳解。
上面的兩個方法都可能造成數據不一致性的問題,具體作法如下:
- 當訂單寫入 t_order_buyer Table後,立即寫入MQ
- 成功寫入 t_order_seller Table後,再把相同的資料寫入MQ
- 當 MQ的 Custermer 在第一個Message 進來後的
兩秒內沒收到第二條 Message,就可以認為數據不一致,需要進行數據補償動作,這一系列操作稱為:線上檢測補償。
進行數據補償動作之前需要進行200-Areas/230-知識擴展/讀書筆記/冪等操作
實際做法
直接建立兩個List<string> buyerData、List<string> sellerData,一旦兩個List數據不一致就進行數據補償
Demo程式碼
