SRE計畫書
網站可靠性工程(SRE)
增加系統可靠度
目的
使用網站可靠性工程 (SRE) 工具,來自動執行多項操作工作,並提高團隊效率。
- 網站可靠性工程(SRE)是使用
軟體工具自動化 IT 基礎架構任務。 - 確保其軟體應用程式在開發團隊的
頻繁更新中保持可靠性。 提高可擴展軟件系統的可靠性,使用軟件管理系統比手動管理機器更具可持續性。
SRE關鍵原則
- 改善協作
- 逐步變革實作,改善開發與營運團隊之間的協作
- 增進客戶體驗
- 應用程式監控,來確保軟體錯誤不會影響客戶體驗
- 改善操作規劃
- 自動化以改善可靠性,團隊接受軟體失敗的可行機會
建立制度與文化
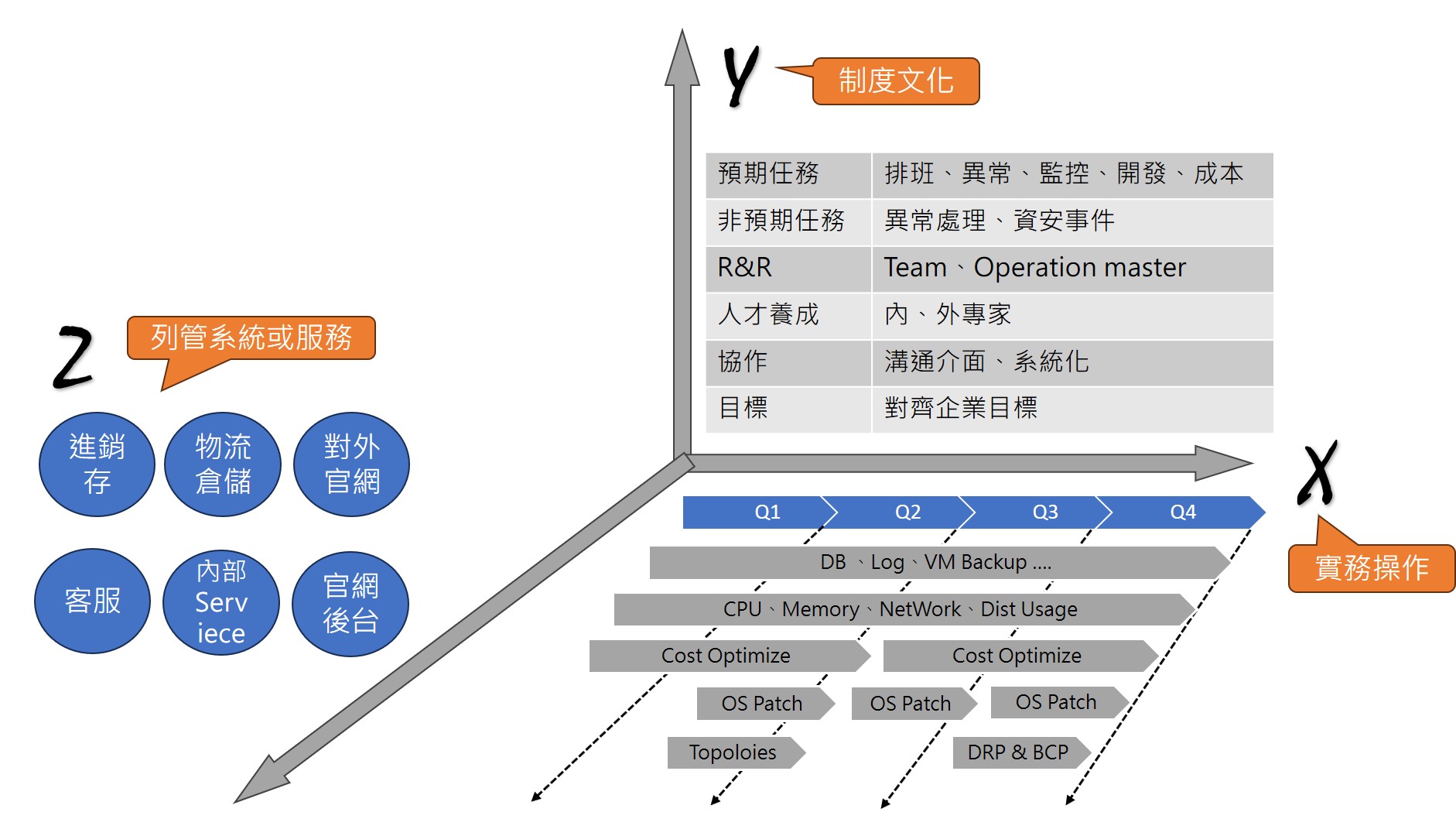
- 個人角度:累積與重複使用,每次跌倒都有成長
- 團隊
- 有限資源下,滿足On Call需求大家才能安心放假,避免公車效應(某個關線人物出意外導致整個專案無法進行)
- 有章法、組織性、有陣型的執行任務,才可以規模話、系統化。
- 傳承、知識共享
- 企業:減少成本、提升可靠度、擴展業務
事件處理
期望結果
整個組織面對計畫中、非計劃性的任務,都能夠有一致的協作處理辦法,尤其針對非計畫性的危機處理更是著重地方。
todo
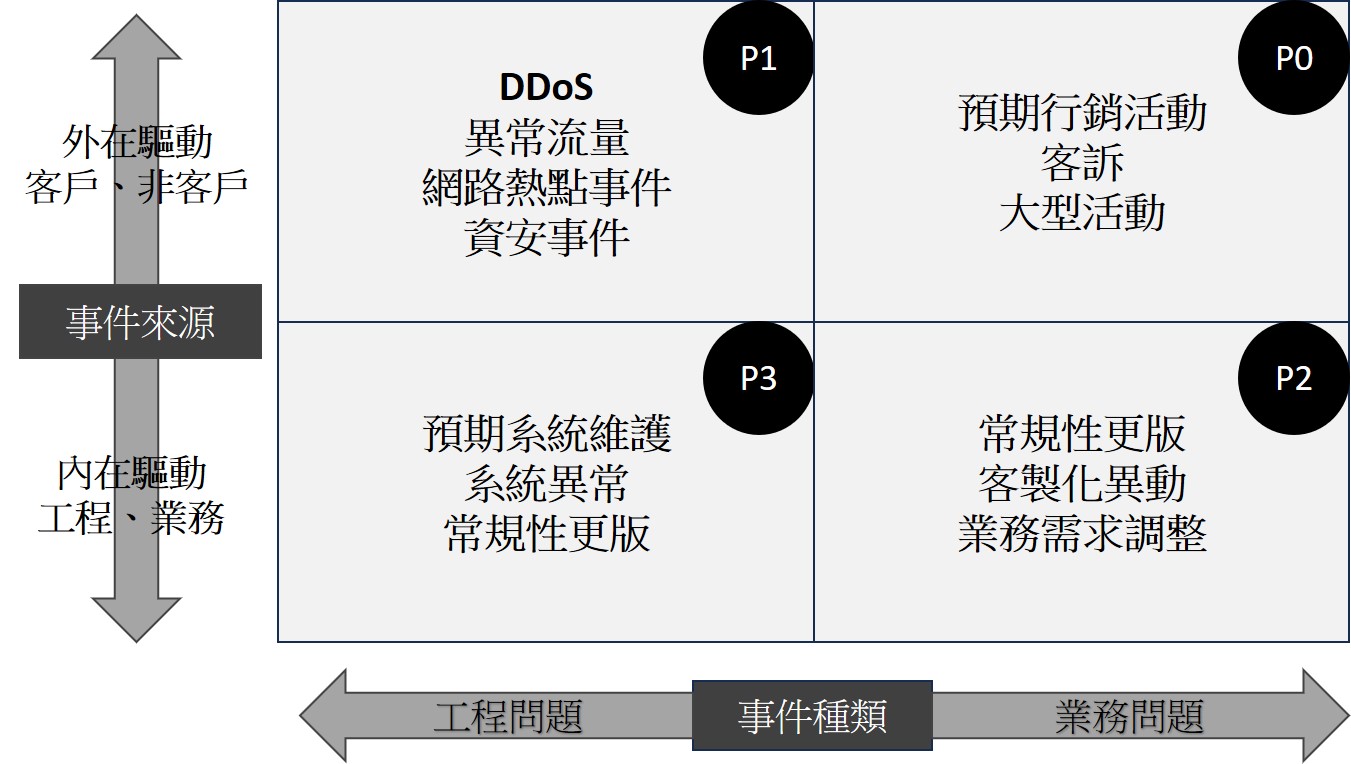
定義出P1~3的等級與事件後才有辦法定義出處理時間。
團隊一起列出過去曾經發生的具體異常事件,判斷優先次序、事件種類、事件來源,每季重新整理一次。
- 優先序
- 嚴重性
- 事件來源
- 事件種類
危機處理-管理溝通流程
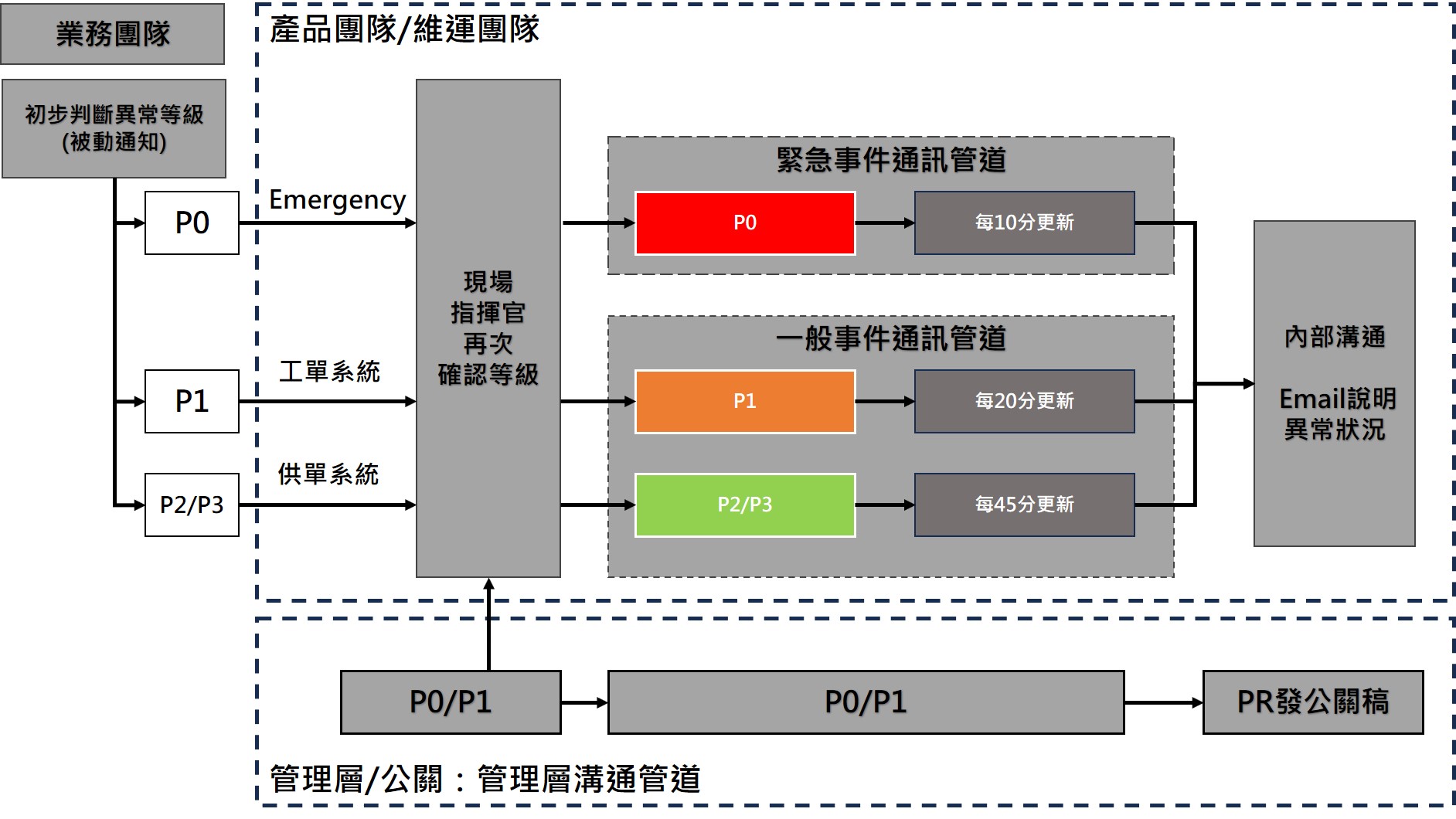
- P0 客訴處理(10分鐘更新進度):由業務維運第一線處理。如重大活動、客訴需要搭配【公關與危機管理】,擬定內外應變計畫。
- P1 工程問題(20分鐘更新進度):由SRE監控發現與處理,像是異常流量、DDOS攻擊、網路熱點事件
- P2 內部工程問題(45分鐘更新進度):開發過程常規性異動,如交付流程與部署沒有處理好、k8s出現異常。
- P3 內部維運問題(45分鐘更新進度):維運工程團隊的工作項目,自發性的驅動、非預期的驅動。
計畫性任務
預計建立 Redmin作為ISMS以期望達到符合ISO27001 第9項【績效評估】
- 組織應評估
資訊安全績效及資訊安全管理系統之有效性。 - 組織應決定下列事項。
- (a)需要監督及量測之事項,包括
資訊安全過程及控制措施。 - (b)
監督、量測、分析及評估之適用方法,以確保有效的結果。 - (c)執行監督及量測之時間。
- (d)監督及量測之人員。
- (e)監督及量測
結果應分析及評估之時間。 - (f)分析及評估上述結果之人員。
- 組織應保存適切之
文件化資訊,作為監督及量測結果的證據。
- 組織應保存適切之
- (a)需要監督及量測之事項,包括
訓練與事件報告
建立文件管理系統, 透過進行事故後審查,來改善軟體開發生命週期。將所有軟體問題和相應的解決方案記錄在共用知識庫中。幫助軟體團隊在未來高效地應對類似問題。
具體報告內容
- 事件當下的紀錄
- 事後處理與修復
- 統計與分析
| 欄位 | 說明 | 範例 |
|---|---|---|
| 事件摘要 | 句話描述事件的關鍵字、影響 | WebAPI的商品頁資回應很慢,使用者無法瀏覽商品資訊。 |
| 詳細描述 | 詳細描述狀況。 | WebAPI商品頁資訊透過瀏覽器與APP 突然回應很慢,很多圖檔無法顯示, 導致客戶的使用者無法瀏覽商品資 訊°其他客戶並沒有這樣狀況° |
| 發現時間 | 發現的時間點。 | 2023/3/1 21:00 |
| 發現方式 | 描述是內部還是外部發現。如果是內 部,要記錄哪個團隊、透過什麼方式' 像是自動化、人工。 |
範例1 :客戶(編號:A00001)回報 給業務。 範例2 :內部Ninja團隊的監控機 制發現。 |
| 影響範圍 | 描述影響的範圍。 | 範例1 : WebAPI的所有使用者。 範例2 :全部的客戶 |
| 嚴重性 | 當下判斷的嚴重性等級'分成S0〜S3。 | S0 |
| 優先序 | 當下判斷處理的優先序‘分成POP3。 | P0 |
事後處理與修復格式
| 欄位 | 說明 | 範例 | |
|---|---|---|---|
| 問題原因(Root Cause) | 針對問題做深度的分析。 | 使用AWS EFS存放圖檔‘ Read IOPS Credit耗盡,造成無法正常回覆圖檔資料給WebSite。 | |
| 處理方式 | 詳細描述處理的過程與方式。 | •提高 EFSIOPS Credit 從 500— 2000。 •增加CDN快取,減少圖檔存取的次數 |
|
| 後續行動 | 描述後續的處理工作項目,包含任務內容與負責團隊。 | •調整U RL Path •讓CDN更容易設定圖檔-SRE+Ninja。 •使用預熱方式,讓CDN能夠先針對圖檔路徑預熱-SRE。 •增加EFS IOPS檢查機制,提早發現-SRE。 |
|
| 未來如何提早發現 | 類似問題-有沒有什麼方法可以提早避免或者發現的? | 後續行動(3 ) | |
| 人力與成本 | 描述這次共有多少人參與?花費多少時間? | 3個人參與,過程耗費]小時:Total= 3X 1=3小時/人力 |
摘要報告
- 標題:[P0] 2023/03/01 (三) 13:30~15:30 商品業回應很慢,客戶無法下單
- 異常時間:2023/03/01 13:30。
- 如何發現:Ninja團隊的監控機器人發現
- 異常原因:AWS儲存服務EFS的Credit耗盡,造成無法存取讀檔。
- 處理方式:調整 EFS Credit 500 — 2000。
- 後續行動
- 調整URL Path讓CDN更容易設定圖檔-SRE + Ninja。
- 使用預熱方式,讓CDN能夠先針對圖檔路徑預熱- SRE。
- 增加EFS IOPS檢查機制,提早發現-SRE (Done )。
- 人力成本:3X1 =3小時/人力
- 未來如何提早發現:增加EFS IOPS檢查機制'提早發現-SRE ( Done )。
SRE關鍵指標
架設監控系統ELK建立 系統關鍵成效、服務水平協定(SLA)、服務目標(SLO)、服務指標(SLI)
- SLA
- 服務:電子商務網站 API 串接服務
- 服務級別:24/7
- 可用性:95%
- 回應時間:1 小時內
- 解決時間:4 小時內
- SLO目標
- WEB 一小時以內 ,Status = 200 > 95%、timetake < 500ms
- SLI目標
- 500ms的請求延遲
- HTTP status = 200 次數與回應次數的比率
SLO 95%視覺化圖表
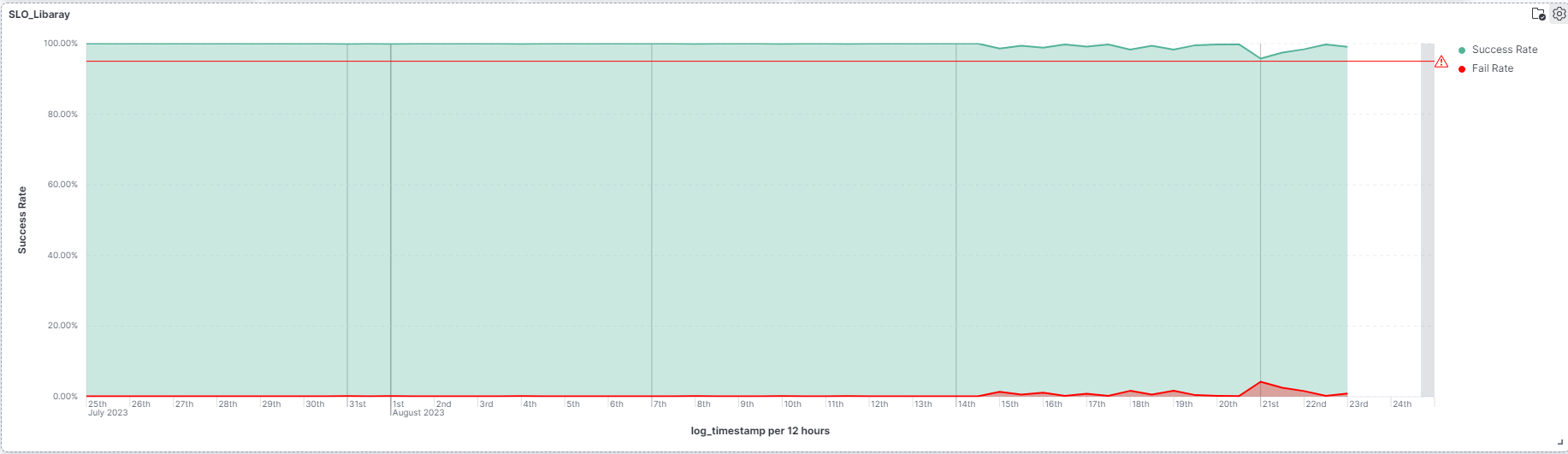
系統關鍵指標(SKM)
I/O Blocking造成資料庫查詢效能不好、存取盪按時磁碟反應慢、Deadlock資源競爭- 資源使用率:CPU、Memory、Disk Size
- I/O狀態:Network I/O Throughput、Disk的IOPS
- 網路層:Load Balancer 的 HTTP 5xx、4xx、3xx、2xx數量
- 內部服務的通訊:API對DB的QPS(Query Per Secend)、對Queue的操作請求
- 服務對外的通訊:RPS(Request Per Second)、HTTP 5xx、4xx、3xx、2xx數量
業務關鍵指標 (DKM)
- 訂單總數(已結、未結、在途)
- 包裹損壞數量
- 客訴總數,客訴類型分析
- 網站進入總數...等等
日常監控計畫(規範、制度、原則)



- 每天:資料庫完整備份、Log備份、虛擬機備份、刪除舊的備份
- 每週:了解系統狀況,各指標是否異常,不符合SLO定義的,備份狀況檢查
- 每月:系統監控趨勢複查、成本複查、軟體更新、網路流量複查
- 每季:作業系統資安更新、軟體套件更新資安更新、Public IP管制列表、資料還原演練,系統異常演練、架構複查、權限複查等
- 每年:防災演練、網路防火牆複查、資源使用政策調整、防火牆政策、網路拓樸架構負複盤、SSL購買
系統架構可靠度設計
網站可靠性工程師與開發團隊密切合作,以創造新功能並穩定生產系統。為整個軟體團隊建立 SRE 程序,並隨時支援升級問題。為產品團隊支援提供文件化程序,以協助他們高效地處理客訴。
系統設計:包含API設計、Configuration/Ioc、架構設計、部屬策略、可靠度設計、監控指標設計等
系統開發作業標準化
- 觀念統一達成共識
- 統一命名規則
- 命名規則一致,增加閱讀性
- 重構-改善現有程式碼
- 分享開發技巧、提升撰寫能力
- 導入GitLab
- 標準化GitFlow
- 統一控管 Branch 、Issue
- 導入看版控管專案進度
- 統一命名規則
應用程式監測與優化
- 蒐集應用程式Log,進行效能監測
- 錯誤率監測
- 定期觀察資料庫指標、清理索引
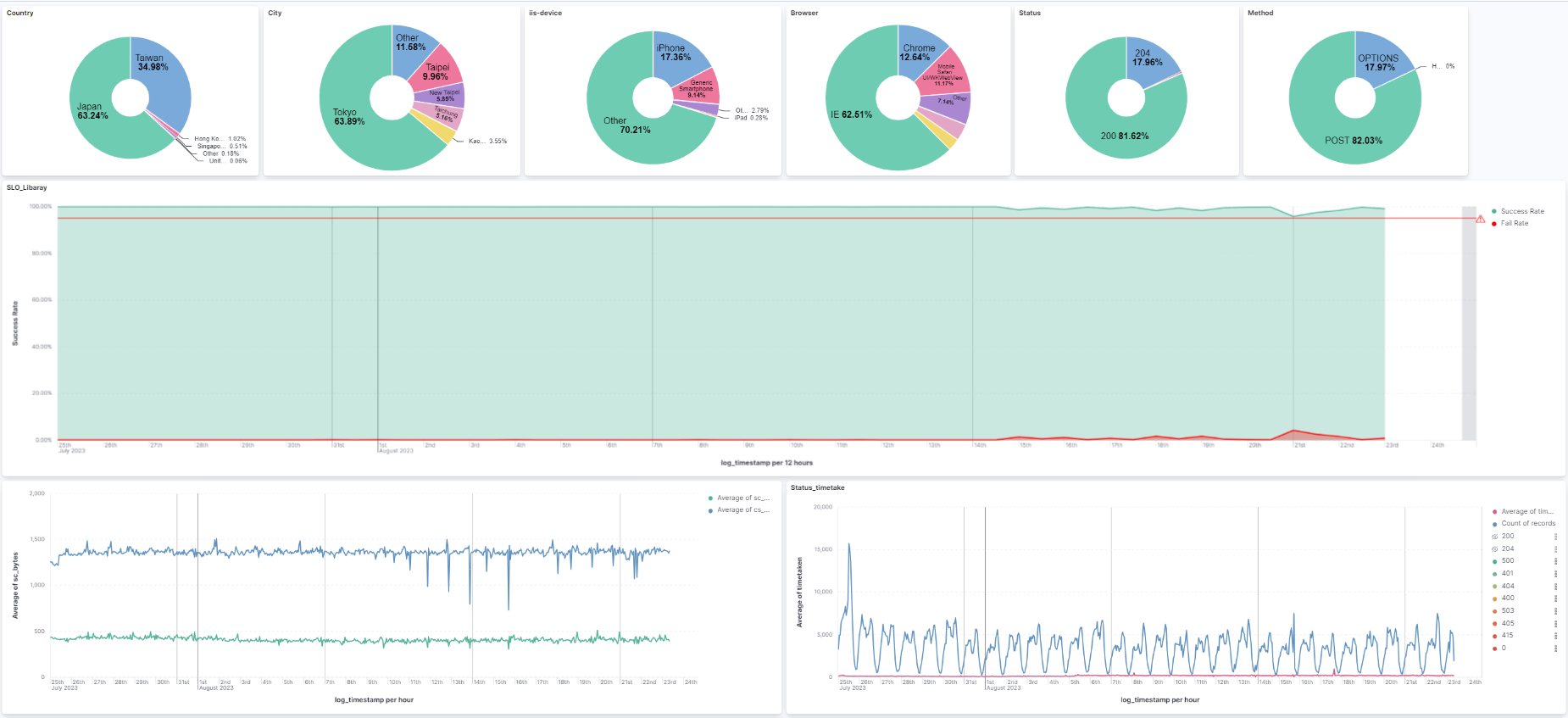
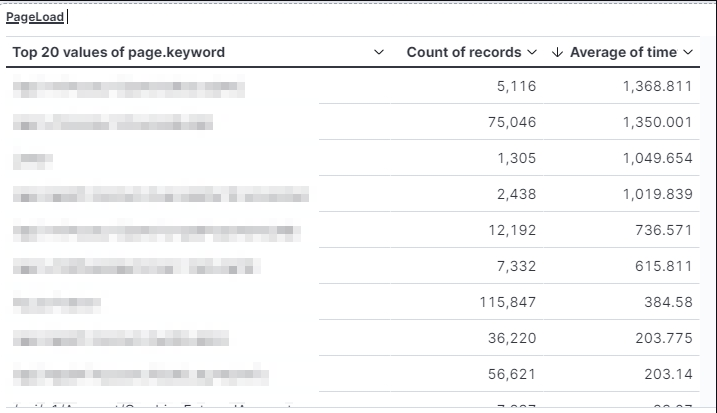
測試策略與自動化
- 導入使用k6進行整合測試、壓力測試
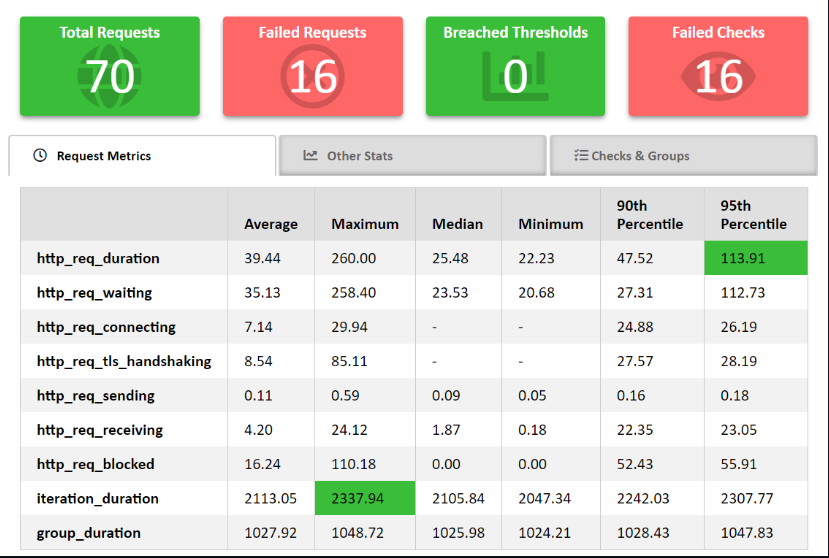
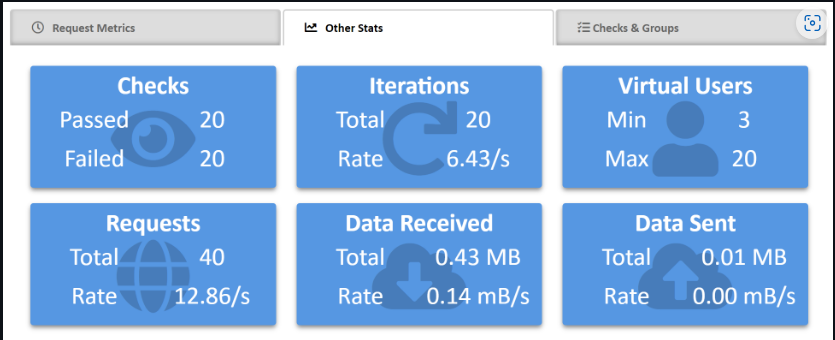
自動化部署機制(CI/CD、Docker、K8S)
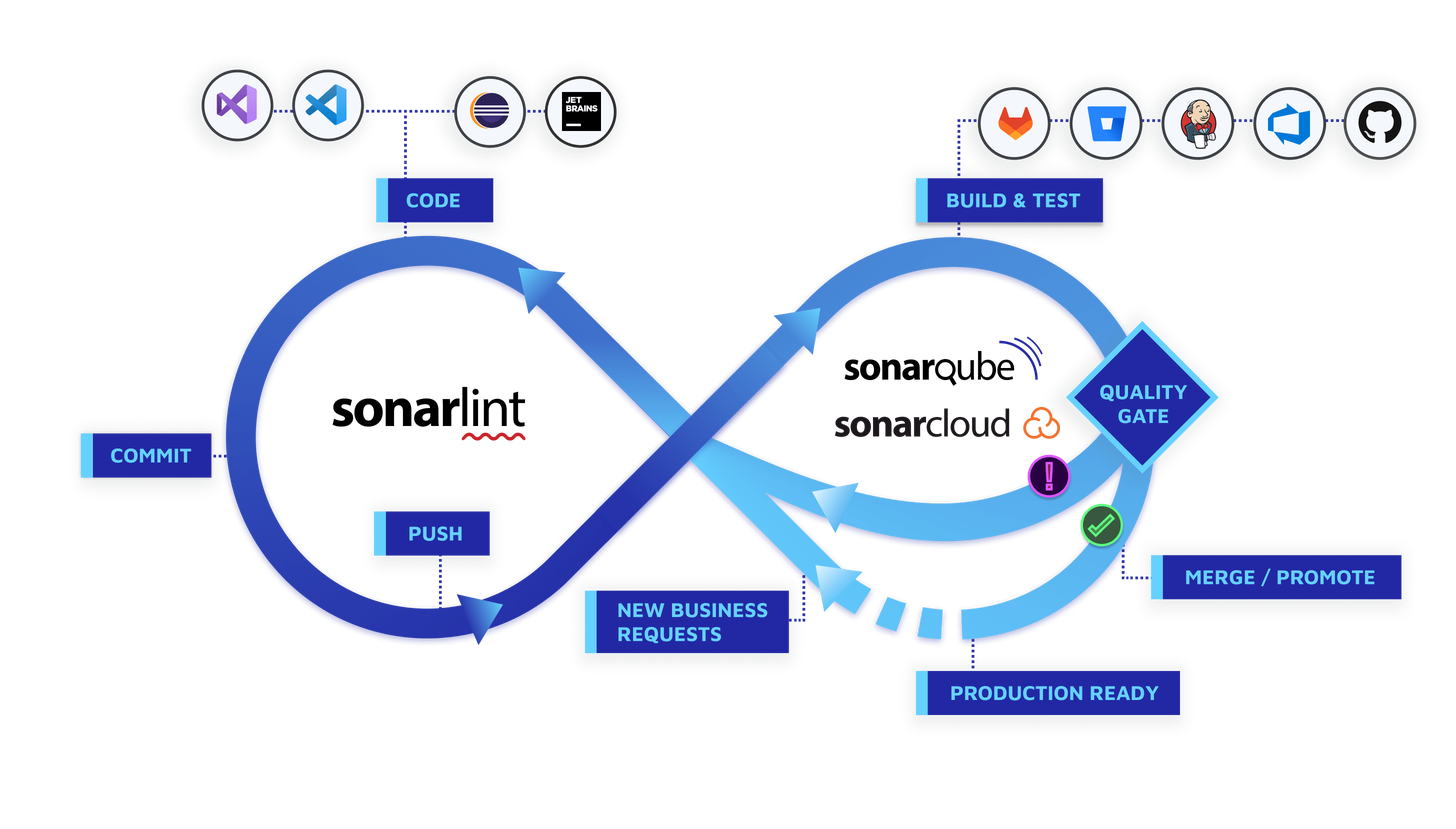
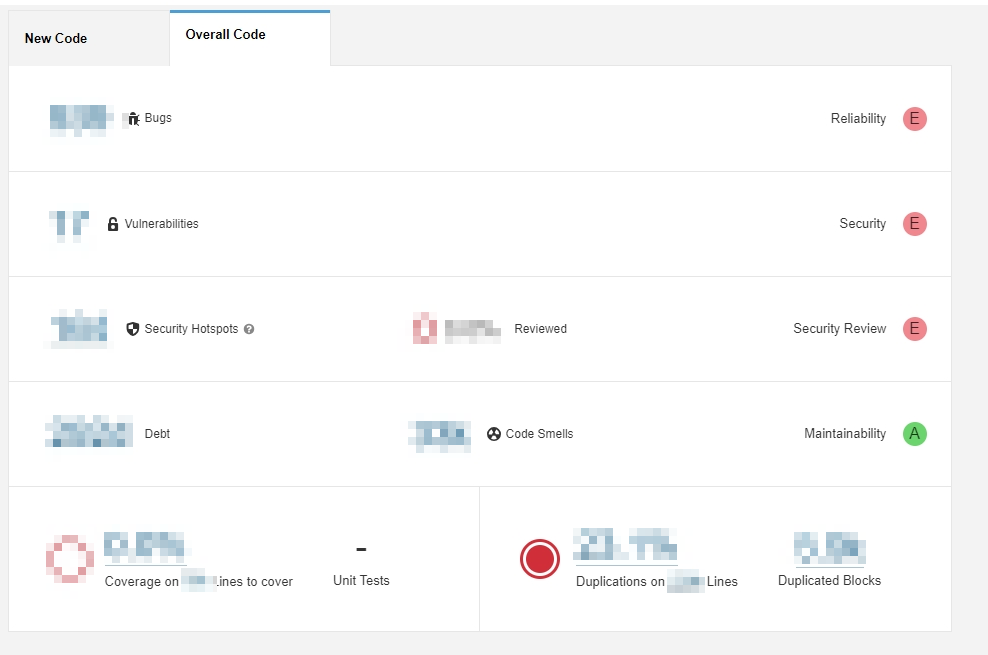
- 穩定程式碼品質
- 推動審核機制(CodeReview)
- 工具輔助檢測程式碼品質(SonarQube)
- 藍綠部署(Ansible)
外部資源
- 每年弱點掃描、 定期滲透
- 資訊安全顧問(導入)
- 個資小組成立
整體預期目標
- 強化監控與快速響應:優化監控系統,關注關鍵指標,迅速識別異常,快速響應問題,以確保系統運行順暢。
- 資訊安全與防禦:加強資訊安全,持續採取弱點掃描、滲透測試等措施,保護系統免受威脅和攻擊。
- 卓越可靠性與擴展性:持續利用SRE方法,自動化IT基礎任務,提升系統可靠性,實現高度擴展性,以應對快速變化的需求。
- 優化客戶體驗和業務成果:通過改善協作和客戶體驗,確保高滿意度,實現順利的業務運營和成功。